MiniMax M2.7: The 10B Model That Beats Claude and GPT on Coding Benchmarks
MiniMax, a Shanghai-based AI company, released M2.7 on March 18, 2026. The model uses a Mixture of Experts architecture with only 10 billion active parameters — the smallest model to reach Tier-1 performance. It costs $0.30 per million input tokens and $1.20 per million output tokens, making it roughly 50 times cheaper than Claude Opus 4.6 and 25 times cheaper than GPT-5.
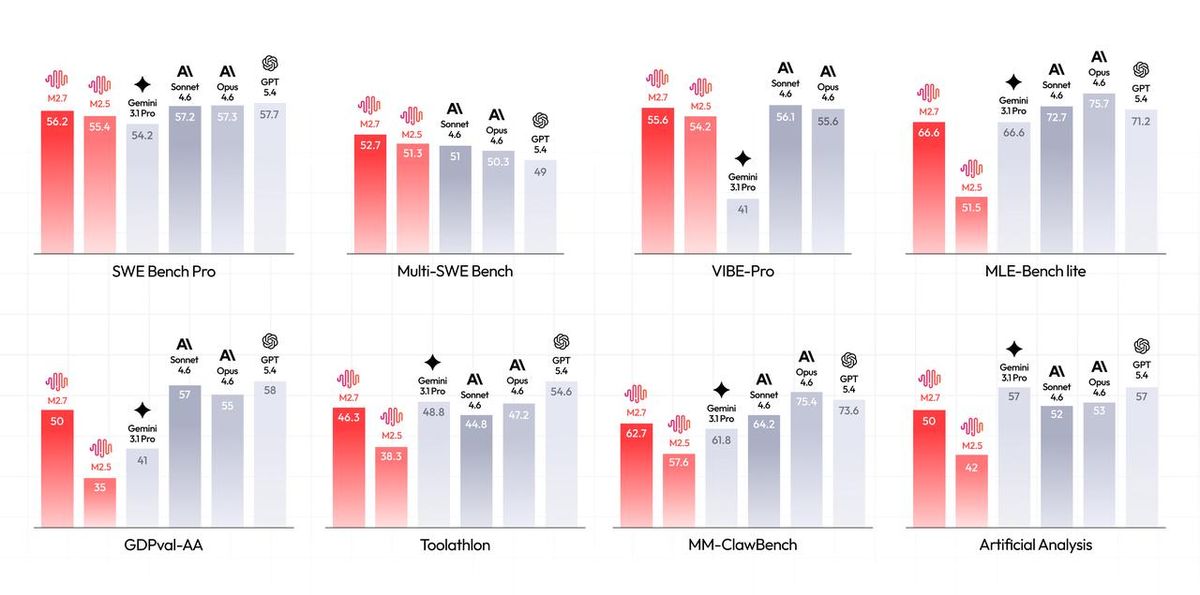
The headline numbers are real. On SWE-Bench Verified, M2.7 scores 78%, compared to Claude Opus at 55%. On Artificial Analysis Intelligence Index, it ranked first out of 136 models. On MLE-Bench Lite, it ties with Gemini 3.1 Pro at 66.6%. These are not cherry-picked results across a handful of tasks — the model performs consistently across software engineering, tool use, and professional productivity benchmarks.
Self-evolving: the model that built itself
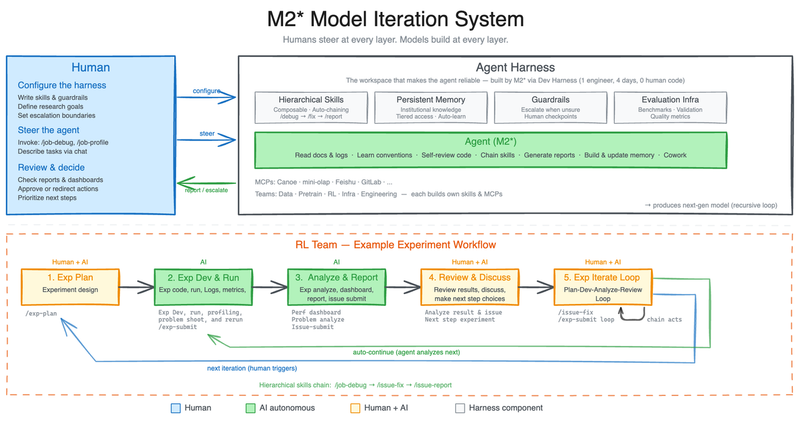
The most unusual claim about M2.7 is how it was trained. MiniMax describes it as the first commercial model that deeply participated in its own evolution. During development, M2.7 was given access to its own training pipeline — analyzing failure trajectories, planning changes to its scaffold code, running evaluations, and deciding whether to keep or revert modifications.
This recursive self-optimization loop ran for over 100 iterations. MiniMax reports a 30% performance improvement on internal benchmarks from this process alone. The model also handled 30 to 50 percent of the reinforcement learning research team's workflow autonomously. This is not traditional RLHF or instruction tuning. It is closer to a model acting as its own research engineer.
Benchmark breakdown
On software engineering tasks, M2.7 scores 56.2% on SWE-Bench Pro, within one point of Claude Opus 4.6 and Gemini 3.1 Pro. On Multi-SWE-Bench, which tests multi-repository changes, it leads at 52.7%. On VIBE-Pro, which measures coding agent reliability, it scores 55.6%, matching Sonnet 4.6. These are not toy benchmarks — they measure whether a model can actually fix real bugs in real codebases.
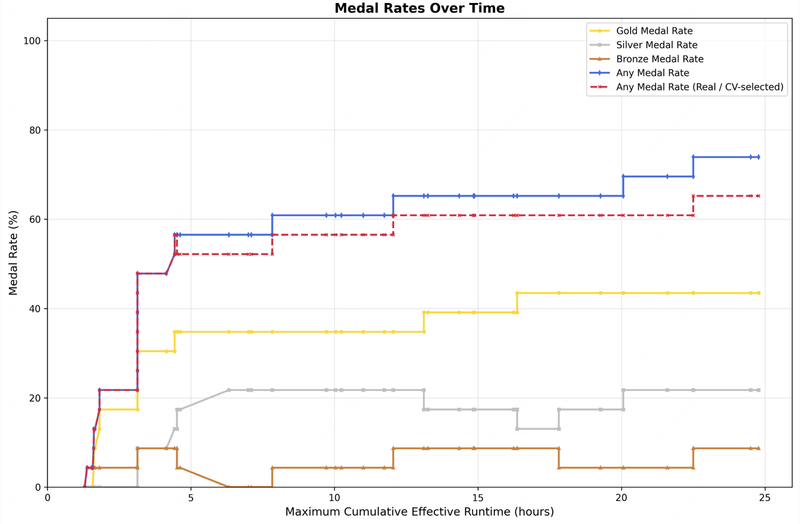
On professional productivity, M2.7 achieves a 1495 ELO on GDPval-AA, the highest among comparable models. Its tool use accuracy on Toolathlon is 46.3%, and on MM-ClawBench it reaches 62.7%, approaching Claude Sonnet 4.6. On machine learning tasks, MLE-Bench Lite shows a 66.6% medal rate, tying Gemini 3.1 Pro. The model earned 9 gold, 5 silver, and 1 bronze in its best single run.
Speed and cost advantage
M2.7 runs at approximately 100 tokens per second on MiniMax's infrastructure — roughly three times faster than Claude Opus 4.6 and two and a half times faster than GPT-5. The cost difference is even more dramatic. Input tokens cost $0.30 per million compared to Claude Opus at $15 per million. Output tokens cost $1.20 per million compared to $75 per million. That is a 62x cost reduction on output for comparable benchmark performance.
A higher-speed variant, M2.7-highspeed, doubles the throughput at double the price — still dramatically cheaper than competitors. Both variants support a 205K token context window, equivalent to roughly 307 pages. The model is available through MiniMax's API platform and is compatible with Claude Code, Cursor, Cline, and other OpenAI-compatible harnesses.
What this means for the market
M2.7 is not open source — unlike MiniMax's earlier M2 and M2.5, the weights for M2.7 are proprietary. This is a pivot. The company is betting that API revenue at extremely low prices can outcompete both premium closed models and open-weight alternatives. At these price points, the cost of using a frontier-class model drops below the cost of running open models on your own hardware.
The self-evolving training approach also signals where the industry is heading. If models can meaningfully participate in their own improvement cycles, the bottleneck shifts from human researcher hours to compute and evaluation infrastructure. MiniMax claims M2.7 replaced 30 to 50 percent of their RL team's work. Whether other labs can replicate this remains to be seen, but the direction is clear: models are becoming collaborators in their own development.