MiniMax M2.7: نموذج بـ10 مليارات معامل يتفوق على Claude وGPT في البرمجة
أصدرت MiniMax، شركة ذكاء اصطناعي مقرّها شنغهاي، نموذج M2.7 في 18 مارس 2026. يستخدم النموذج هيكلية مزيج الخبراء بـ10 مليارات معامل نشط فقط — أصغر نموذج يصل أداء الطبقة الأولى. يكلّف 0.30 دولار لكل مليون رمز إدخال و1.20 دولار لكل مليون رمز إخراج، ما يجعله أرخص نحو 50 مرة من Claude Opus 4.6 و25 مرة من GPT-5.
الأرقام الرئيسية حقيقية. في SWE-Bench Verified، يسجّل M2.7 نسبة 78% مقابل 55% لـClaude Opus. في مؤشر Artificial Analysis Intelligence حلّ أولًا من بين 136 نموذجًا. في MLE-Bench Lite، يتعادل مع Gemini 3.1 Pro عند 66.6%. هذه ليست نتائج منتقاة من مهام محدودة — النموذج يقدّم أداءً متسقًا عبر معايير هندسة البرمجيات واستخدام الأدوات والإنتاجية المهنية.
التطوّر الذاتي: النموذج الذي بنى نفسه
الادعاء الأكثر غرابة حول M2.7 يتعلق بكيفية تدريبه. تصفه MiniMax بأنه أول نموذج تجاري شارك بعمق في تطوير نفسه. أثناء التطوير، أُتيح لـM2.7 الوصول إلى خط أنابيب التدريب الخاص به — يحلل مسارات الإخفاق ويخطط تعديلات على شيفرة الهيكل ويجري التقييمات ويقرر الاحتفاظ بالتعديلات أو التراجع عنها.
هذه الحلقة التكرارية الذاتية استمرت أكثر من 100 دورة. تفيد MiniMax بتحسّن 30% في الأداء على المعايير الداخلية من هذه العملية وحدها. كما أنجز النموذج 30 إلى 50 بالمئة من عمل فريق التعلم المعزز تلقائيًا. هذا ليس ضبطًا تقليديًا بملاحظات بشرية أو تعليمات. إنه أقرب إلى نموذج يعمل مهندس أبحاث لنفسه.
تفصيل المعايير
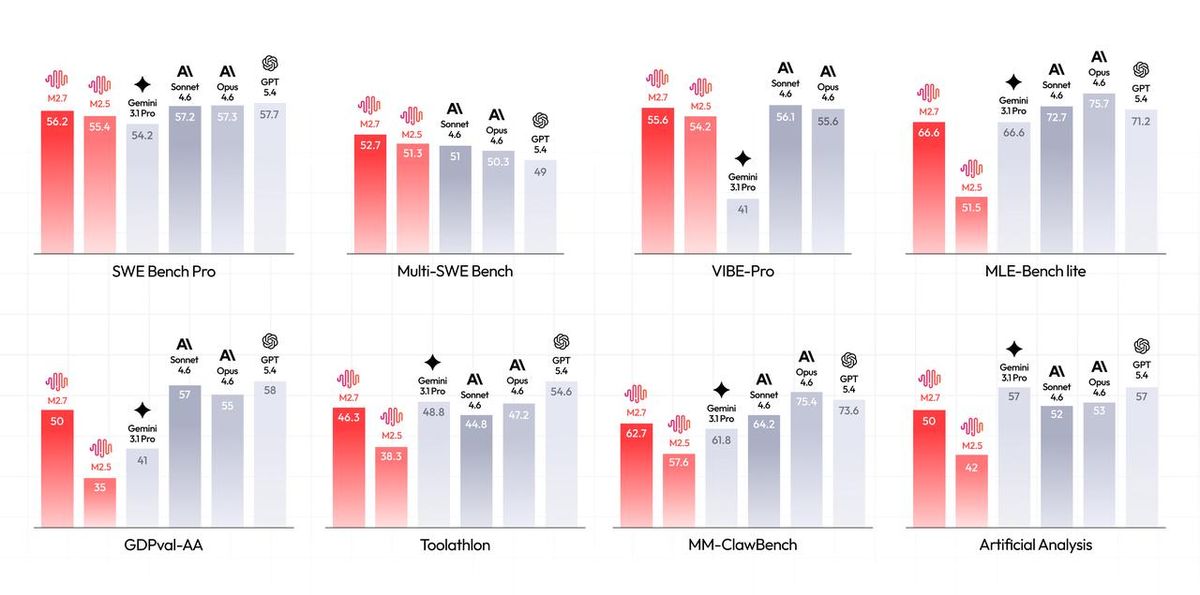
في مهام هندسة البرمجيات، يسجّل M2.7 نسبة 56.2% في SWE-Bench Pro، ضمن نقطة واحدة من Claude Opus 4.6 وGemini 3.1 Pro. في Multi-SWE-Bench الذي يختبر التعديلات عبر مستودعات متعددة يتصدر بنسبة 52.7%. في VIBE-Pro الذي يقيس موثوقية وكلاء البرمجة يسجّل 55.6% مطابقًا Sonnet 4.6. هذه ليست معايير لعب — بل تقيس قدرة النموذج على إصلاح أخطاء حقيقية في مستودعات شيفرة فعلية.
في الإنتاجية المهنية يحقق M2.7 تقييم 1495 ELO في GDPval-AA، الأعلى بين النماذج المقارنة. دقة استخدام الأدوات في Toolathlon تبلغ 46.3%، وفي MM-ClawBench يصل 62.7% مقتربًا من Claude Sonnet 4.6. في مهام تعلم الآلة، MLE-Bench Lite يظهر معدل ميداليات 66.6% متعادلًا مع Gemini 3.1 Pro. حصل النموذج على 9 ذهبيات و5 فضيات وبرونزية في أفضل جولة منفردة.
ميزة السرعة والتكلفة
M2.7 يعمل بسرعة نحو 100 رمز في الثانية على بنية MiniMax التحتية — أسرع ثلاث مرات تقريبًا من Claude Opus 4.6 ومرتين ونصف من GPT-5. فارق التكلفة أكبر. رموز الإدخال تكلّف 0.30 دولار لكل مليون مقابل 15 دولارًا لـClaude Opus. رموز الإخراج تكلّف 1.20 دولار لكل مليون مقابل 75 دولارًا. هذا تخفيض 62 ضعفًا في تكلفة الإخراج لأداء معياري مقارب.
المتغير الأسرع M2.7-highspeed يضاعف سرعة المعالجة بضعف السعر — ويظل أرخص بكثير من المنافسين. كلا المتغيرين يدعمان نافذة سياق بـ205 آلاف رمز، ما يعادل نحو 307 صفحة. النموذج متاح عبر منصة MiniMax وهو متوافق مع Claude Code وCursor وCline وأي أداة متوافقة مع OpenAI.
ماذا يعني هذا للسوق
M2.7 ليس مفتوح المصدر — على عكس M2 وM2.5 السابقين من MiniMax، أوزان M2.7 مملوكة. هذا تحوّل. الشركة تراهن على أن إيرادات واجهة API بأسعار منخفضة للغاية تستطيع منافسة النماذج المغلقة الفاخرة والبدائل مفتوحة الأوزان. بهذه الأسعار، تنخفض تكلفة استخدام نموذج من الطبقة الأولى إلى ما دون تكلفة تشغيل نماذج مفتوحة على أجهزتك.
نهج التدريب الذاتي يشير أيضًا إلى وجهة الصناعة. إن استطاعت النماذج المشاركة فعليًا في دورات تحسينها، ينتقل عنق الزجاجة من ساعات الباحثين البشريين إلى بنية الحوسبة والتقييم التحتية. تدّعي MiniMax أن M2.7 استبدل 30 إلى 50 بالمئة من عمل فريق التعلم المعزز. ما إذا كانت المختبرات الأخرى تستطيع تكرار ذلك لا يزال غير واضح، لكن الاتجاه واضح: النماذج أصبحت شريكة في تطويرها.